Showing
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.0.3.0.1 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.0.3.0.1
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.0.0.0 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.0.0.0
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.0.0.1 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.0.0.1
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.1.0.0 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.1.0.0
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.1.0.1 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.1.0.1
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.2.0.0 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.2.0.0
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.2.0.1 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.2.0.1
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.3.0.0 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.3.0.0
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/tp/2.1.3.0.1 3 additions, 0 deletions...bservations_2000-2019_biweekly_terciled.zarr/tp/2.1.3.0.1
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/valid_time/.zarray 3 additions, 0 deletions...tions_2000-2019_biweekly_terciled.zarr/valid_time/.zarray
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/valid_time/.zattrs 3 additions, 0 deletions...tions_2000-2019_biweekly_terciled.zarr/valid_time/.zattrs
- data/hindcast-like-observations_2000-2019_biweekly_terciled.zarr/valid_time/0.0 3 additions, 0 deletions...ervations_2000-2019_biweekly_terciled.zarr/valid_time/0.0
- docs/screenshots/fork_renku.png 0 additions, 0 deletionsdocs/screenshots/fork_renku.png
- docs/screenshots/gitlab_add_variable.png 0 additions, 0 deletionsdocs/screenshots/gitlab_add_variable.png
- docs/screenshots/gitlab_variables.png 0 additions, 0 deletionsdocs/screenshots/gitlab_variables.png
- docs/screenshots/renku_start_env.png 0 additions, 0 deletionsdocs/screenshots/renku_start_env.png
- docs/screenshots/s2s-ai-challenge-tag.png 0 additions, 0 deletionsdocs/screenshots/s2s-ai-challenge-tag.png
- environment.yml 9 additions, 14 deletionsenvironment.yml
- notebooks/ML_forecast_template.ipynb 415 additions, 0 deletionsnotebooks/ML_forecast_template.ipynb
- notebooks/ML_train_and_predict.ipynb 1214 additions, 0 deletionsnotebooks/ML_train_and_predict.ipynb
source diff could not be displayed: it is stored in LFS. Options to address this: view the blob.
File added
source diff could not be displayed: it is stored in LFS. Options to address this: view the blob.
File added
source diff could not be displayed: it is stored in LFS. Options to address this: view the blob.
File added
source diff could not be displayed: it is stored in LFS. Options to address this: view the blob.
File added
source diff could not be displayed: it is stored in LFS. Options to address this: view the blob.
File added
File added
File added
docs/screenshots/fork_renku.png
0 → 100644
{kind=link}

81.3 KiB
docs/screenshots/gitlab_add_variable.png
0 → 100644
{kind=link}
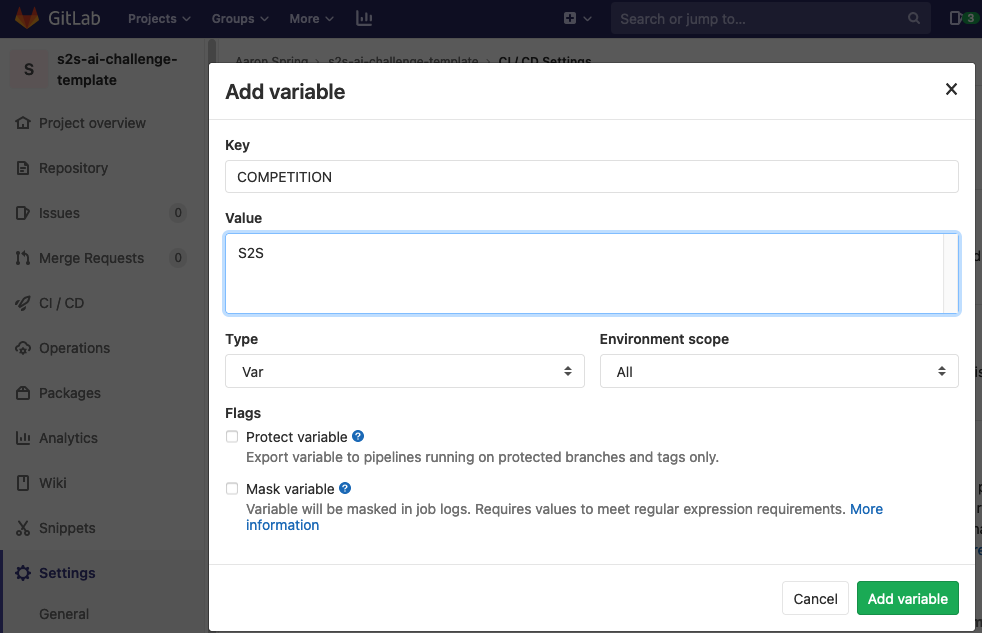
76.2 KiB
docs/screenshots/gitlab_variables.png
0 → 100644
{kind=link}
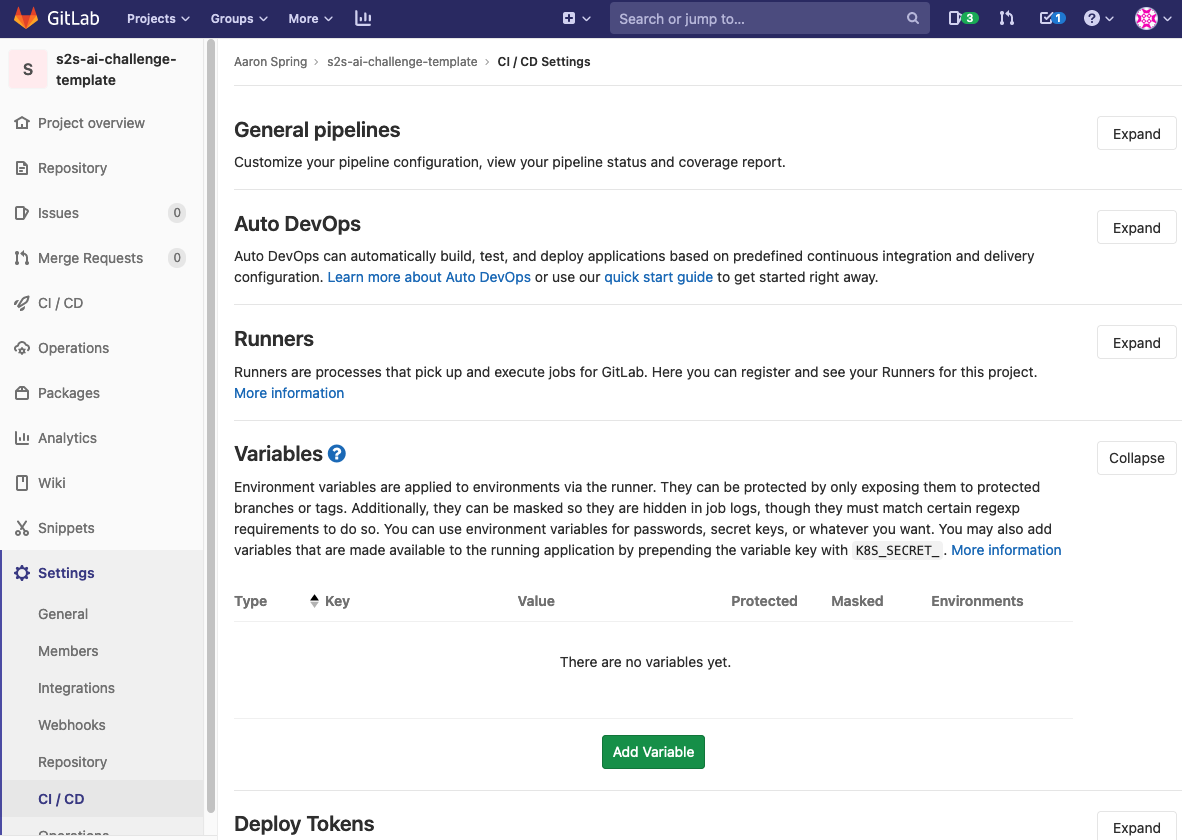
157 KiB
docs/screenshots/renku_start_env.png
0 → 100644
{kind=link}

76.6 KiB
docs/screenshots/s2s-ai-challenge-tag.png
0 → 100644
{kind=link}

45 KiB
notebooks/ML_forecast_template.ipynb
0 → 100644
notebooks/ML_train_and_predict.ipynb
0 → 100644